
Deep Learning-Based Classification Solutions in Security Camera Systems for Narrowing the Search Space
INTRODUCTION
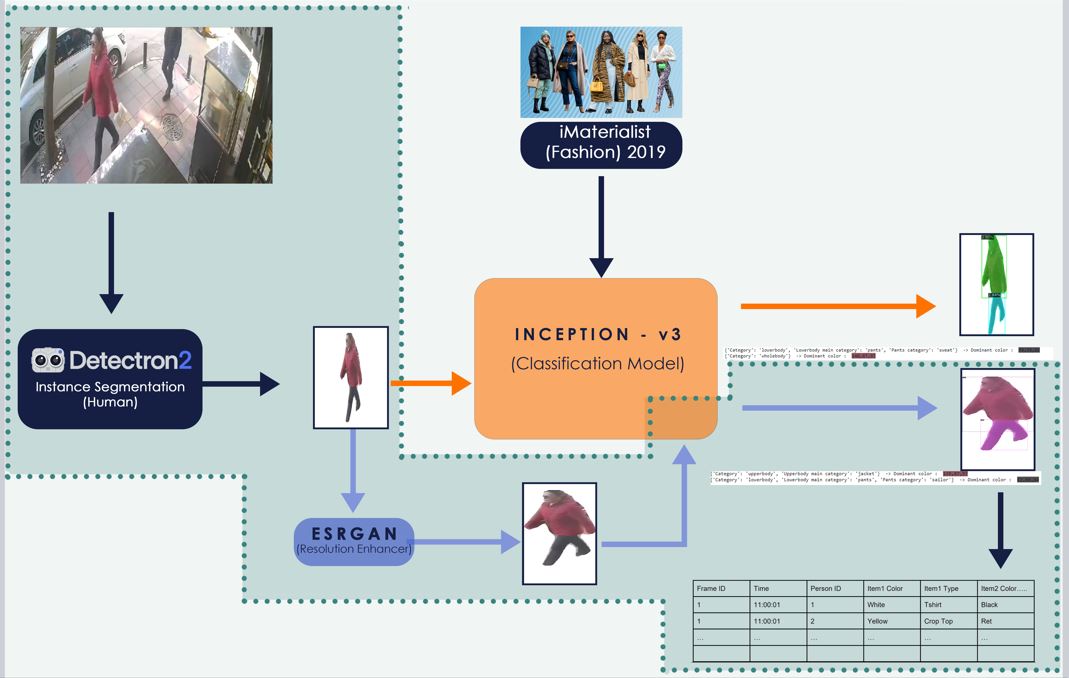
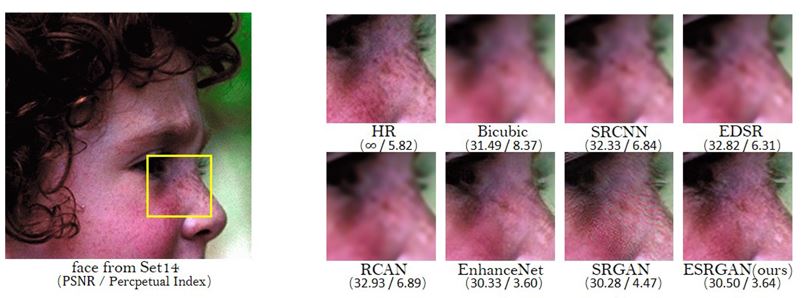
Security cameras (CCTV) are crucial in the modern world and in combating crime. Their presence reduces crime rates and acts as a deterrent for potential criminals, changing behaviors and enhancing security. Traditional methods for examining footage are manual, time-consuming, and labor-intensive. Deep learning-based Al approaches can automate and simplify these processes. In this study, we use Detectron2 for human segmentation, creating regions of interest (ROI) for further analysis. To improve classification accuracy, we enhance the quality of low-resolution images using super-resolution models like SRCNN and Real-ESRGAN. SRCNN effectively recovers details from low-resolution images, VDSR offers improved performance with a deeper network, and Real-ESRGAN provides high-quality, realistic enhancements. These models increase CCTV image resolution, allowing the Inception-v3 model to classify more accurately.
PURPOSE
The main objective of this project, supported by the TUBITAK 2209-A scholarship, is to develop an accessible product that helps prevent the increasing the crime rates and the loss of life and property in cities.
METHODOLOGY
In the first stage, we will train our Detectron2 model "mask_rcnn_R_50_FPN_3x" for instance segmentation using labeled images from the COCO 2017 dataset. As a result of this training, we will be able to segment humans from the input image. The model uses the FPN (Feature Pyramid Networks) architecture in the Backbone neural networks, which form the initial layers. In this structure, we perform three separate convolution operations to extract features at different levels from the input matrix: for low-level features, mid-level features, and high-level features. As the feature level increases, the number of feature maps increases, and the matrix size decreases. As a result, we merge the three matrices that have undergone these convolution operations into a single matrix. The resulting tensor matrix has the same size as the matrix that extracts low-level features and contains as many feature maps as the sum of feature maps at all levels. (numbers are examples)

Following this process, we use the Resnet50 architecture in the further layers of our Detectron2 model. At this stage, we try to capture different features by passing the matrix through lx1 or 3x3 filters. For example, if we pass a matrix through a 1x1 filter with a depth we determine, the output will have a depth, i.e., feature maps, as determined by us. In the final layers, we use the RPN (Region Proposal Network) structure to extract probability scores for proposed regions for objects. This way, our model only tries to recognize objects in the proposed regions, thus performing fewer calculations. As a result of these processes, we apply instance segmentation to the images in our trained dataset and train our segmentation model for use in the following stages.
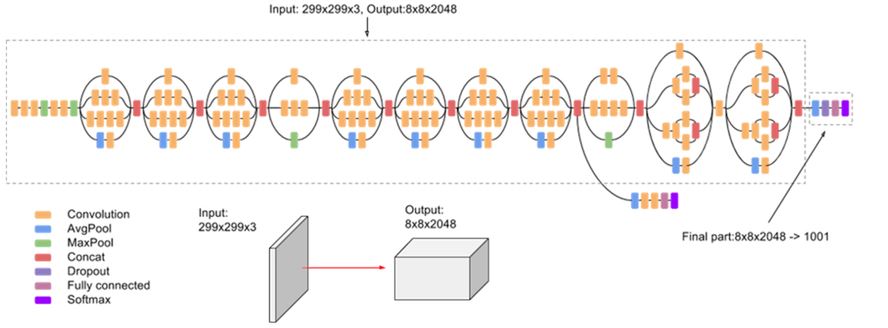
In this study, we used the Inception-v3 model for classification purposes. Inception-v3 is a deep learning model developed by Google that has a high success rate in image recognition tasks. The model performs convolution operations using simultaneous convolutional layers and passing the image through filters such as lxl. This structure allows us to obtain as many feature maps as we want, providing significant flexibility in solving classification problems. Typically trained with large and diverse datasets, we aimed to use the Inception-v3 model trained on the iMaterialist dataset The iMaterialist dataset is a comprehensive and rich dataset that Includes various features and masks of fashion and clothing items. However, a major problem we encountered during the process was that our pretrained model, trained with iMaterialist, failed to classify the low-resolution images from our CCTV footage. To overcome this issue, we applied downsampling to the iMaterialist dataset while preserving the encoded pixels of the masks and attempted to train models such as Inception-v3, mask-RCNN, and Detectron2. Moreover, we achieved the most satisfactory results when we enhanced the image quality using super-resolution methods and then provided these high-resolution images as Input to our existing Inception-v3 model for classification. Super-resolution methods Increase the details of low-resolution images, making them higher resolution and significantly improving the model's classification performance.Through this process, we were able to access detailed information about the clothing on segmented people.
This study aims to enhance low-resolution CCTV images for more accurate classification. We applied super-resolution models such as SRCNN, VDSR, and Real-ESRGAN. Our Inception-v3 model, trained on the high-resolution iMaterialist dataset, showed decreased performance on low-resolution images. Super-resolution models, trained on both high and low-resolution images, help predict low-resolution versions from high-resolution images. Using these super-resolution models, we increased the resolution of CCTV images, enabling the Inception-v3 model to classify more accurately. This approach significantly improves the reliability of security and surveillance systems by enhancing the evaluation of CCTV images.
RESULTS
Classification and dominant color result without ESRGAN:
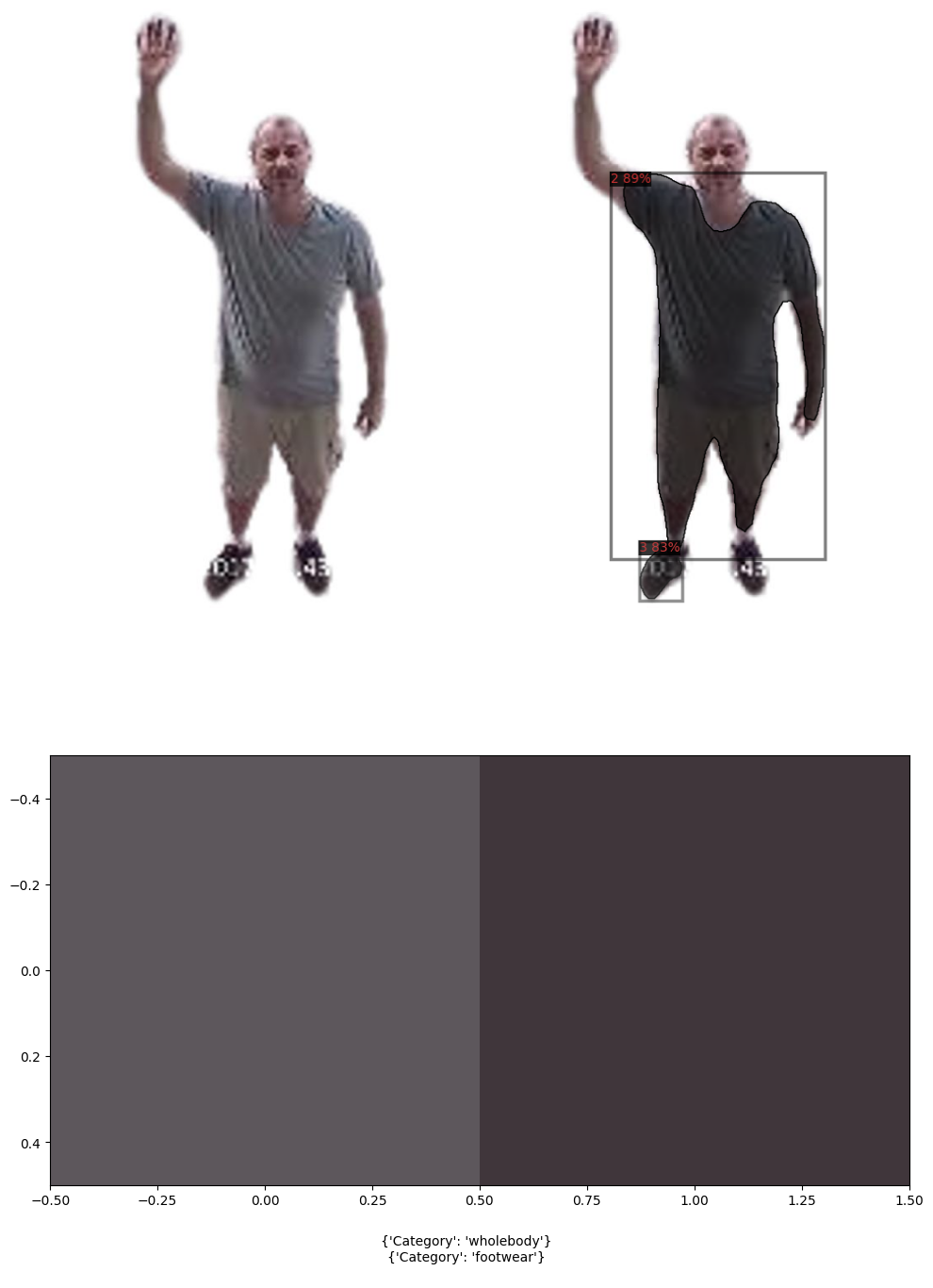
Classification and dominant color result with ESRGAN:
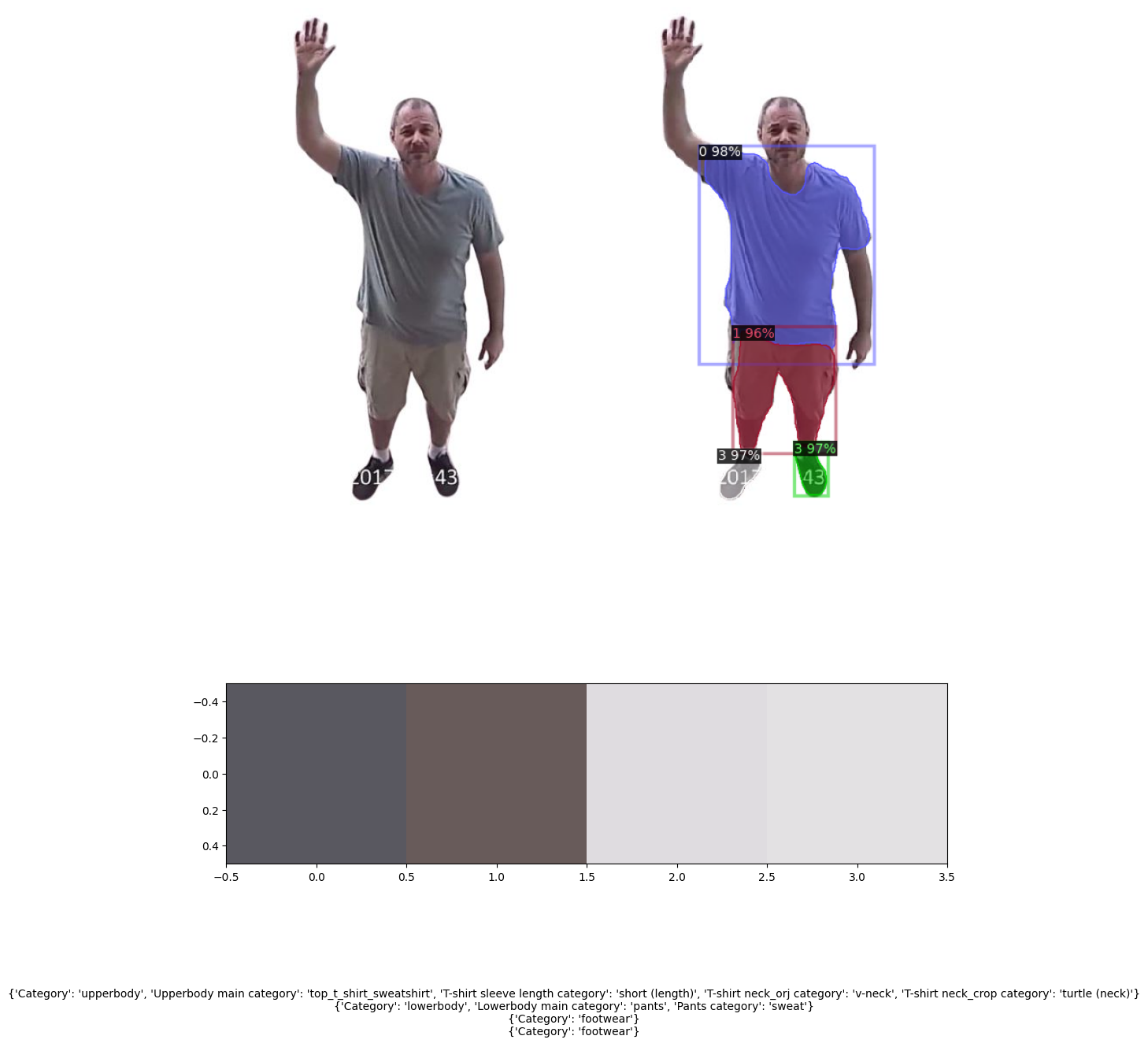
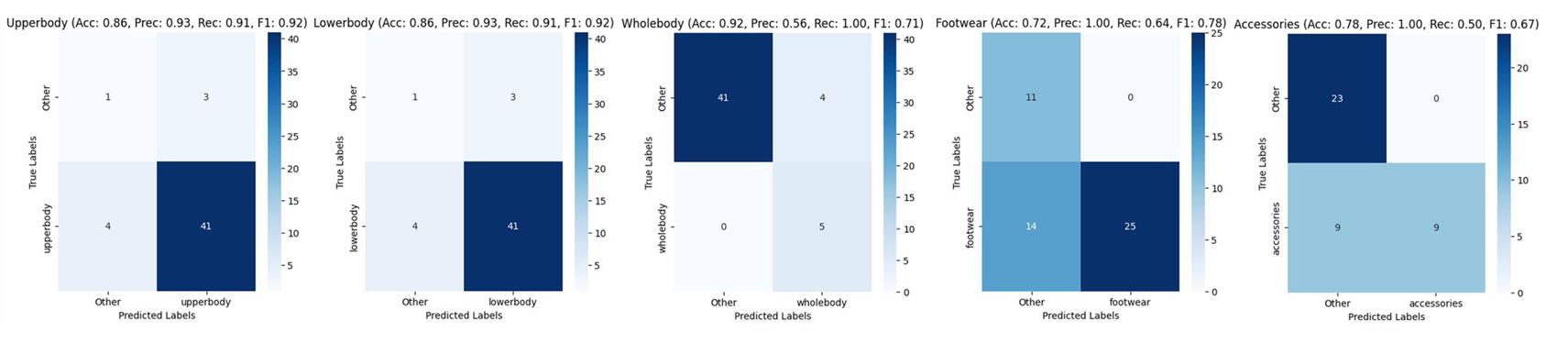
The classification results of 50 CCTV images enhanced using ESRGAN for super resolution with the Inception-v3 model. As can be seen, this is an example of why accuracy should not be the only success metric in unbalanced data:
CONCLUSION
In conclusion, this project aims to enhance the guality of CCTV images and improve classification accuracy using advanced super-resolution models. The data from the classification model will be simultaneously recorded in a database, allowing for more efficient and effective search operations. This further approach will help narrow the search space, significantiy aiding law enforcement in crime prevention and investigation efforts.