
DISASTER AID
ABSTRACT
This project is the report of the project named "Disaster Aid", in which I took part and undertook the leadership to a large extent in the social responsibility course we took in the next academic year, following the process that was carried out in line with the goals of creating solutions urgently in the field and on social media after the Kahramanmaraş Earthquake that deeply shook our country on February 6, 2023.
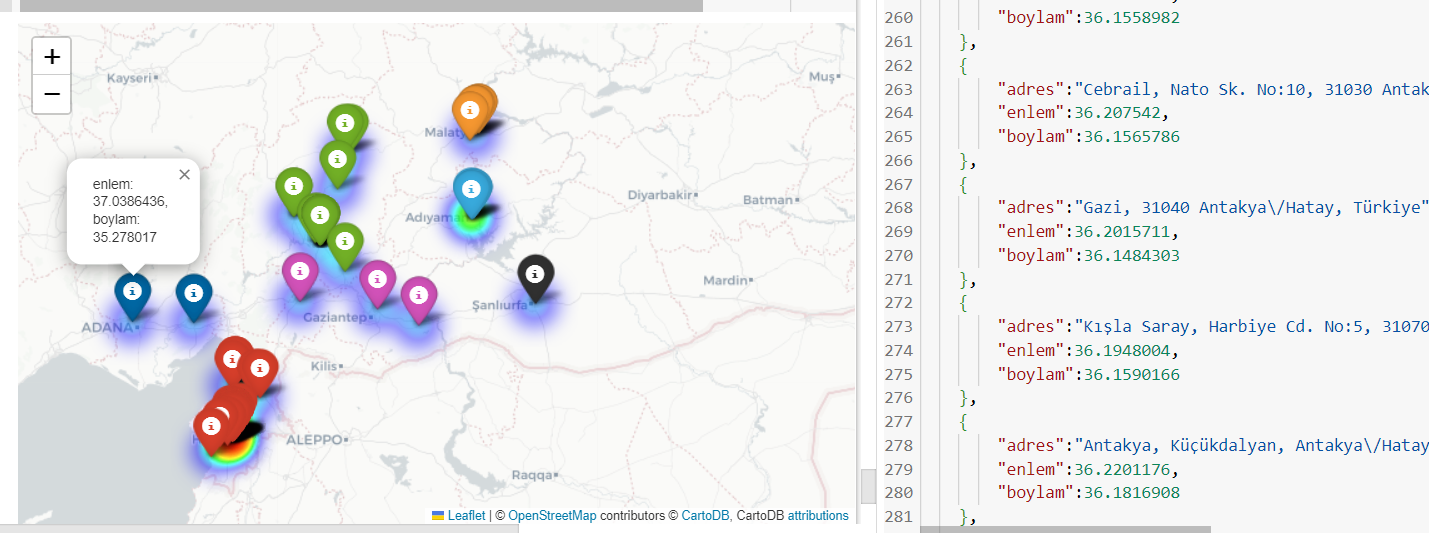
Our project is to create a system where we can access information about the needs of disaster victims who need help during and after a disaster. In this regard, we have aimed to move towards certain areas of work as a team and to bring the project to a whole by proceeding from different branches with a team work. To make a brief summary of how the system we aim for in our project works; If the disaster victim is in a position to reach his phone at that moment, he will be able to send us his needs information with a simple application developed by us, which he has previously downloaded to his phone, and the aid authorities on the other side of the network will be able to access vital information such as the location and needs of the disaster victim through a web panel. Of course, our access to the data of disaster victims cannot be limited to this, because many disaster victims, especially in earthquake disasters, may be in situations where they cannot access their phones or where GSM operators cannot provide internet. Therefore, our biggest treasure in terms of data is social media. For this reason, one of our main goals is to establish a system that will process the data of people affected by the relevant disaster from social media and display it on our web panel. To briefly explain this system; first of all, we chose Twitter as the social media channel because it is both the most frequently used channel in such disaster situations and has more preferable possibilities in terms of obtaining data (API etc.) The most important point at this stage is whether the data we will obtain is “valid” or not. For this, we will use NLP (Natural Language Process) models to determine whether the relevant tweets are relevant to the disaster. Of course, when we think about tweets on Twitter, there are as many visual tweets as there are text tweets, and especially in cases such as earthquakes, since these tweets are shared quite intensively among different users both on other channels and on Twitter, they usually consist of texts written on an image with a picture of the person in need of help. In order to process this data with NLP models, we need to use OCR (optical character recognition) methods. After using this method, after accessing our text data and then questioning whether it is related to a disaster, we come to another important stage. This is to process the text data. Accessing the address information in the text is one of the most important goals for us because our ultimate goal is to show the location of the disaster victims on the map (especially for emergencies such as being under rubble). One of them is to develop an algorithm that we can access address data with NLP, and the other is to obtain address information from our data, which we have previously made certain enrichments with Google Maps API, through this API. We will discuss both of these approaches in detail in the methodology section of our project. We will explain what are the results we have obtained, whether they meet our expectations or what are the steps we have taken to improve them. In the method section, we will also talk about the software we made for the website where we will display all this data and the mobile application that the disaster victim will access. We will also explain in detail with which cloud service we will make our website live.
METHOD
First of all, there are certain steps we need to follow to obtain data. As I mentioned in the summary, we aimed to get our data from Twitter. For this, we used the Twitter API to access the tweets with endpoints and send them to the validation model as they are, if they are text, and if they are images, we used the pytesseract library (we also used the easyocr library, but with less success) to convert the text in the image to text format with OCR. However, we encountered some obstacles in using the Twitter API. This obstacle was that the Twitter API version we used was the free version and unfortunately, we do not have access to the endpoint that will allow us to search tweets in this version. The way to overcome this obstacle is to take advantage of paid versions, and for this we needed a grant within the scope of our project. (We also sent a message to the Twitter Developer team explaining the situation and we are waiting for them to facilitate us for this work). Until this funding was provided, we had to create the data by hand. We created a dataset to develop algorithms to access textual information from images, and we used spaCy's models developed for the Turkish language. We accessed these models from the Hugging Face site and got information. We chose to use spaCy's “tr_core_news_trf” model with transfer learning to access the address information in our dataset. In order to retrieve address information using this model, we tried to use a method where the model follows a certain pattern on the texts in the dataset, but this regex method did not achieve the desired success because the address information in our dataset usually does not follow a certain order. Therefore, we identified certain tags that are likely to appear in the text, such as “neighborhood”, “street”, etc. By doing this, we aimed to make it easier for the model to recognize and distinguish the prepositions containing these tags. We also added more discriminative parameters by adding information from another dataset to our data so that our model can access the address information more easily. We created a json file with Turkey's province and district information. We wrote an algorithm to query with if condition so that our model can better distinguish the province and district names in the text. In other words, we defined a condition to add this information to the address information if this province name is mentioned in the text to our model, which cannot access province or district information in some cases even if it extracts a neighborhood, street and apartment information. Using this method, we reached the address information in a way that can be called successful, but our search for an alternative and more successful way took us to Google Maps API. With this API, which we can use for free, we first extracted the address information from the text, and then we used this API to access the coordinate information for each address in the json file we created with the address information, and we showed these coordinates through the maps provided by the folium library. When we did text-similarity with an address dataset we created by hand to test the accuracy of the address information provided by the Google Maps API, we got very satisfactory results and decided to proceed with this method.
This block diagram represents our modulation and demodulation processes:
We had a dataset problem in our model to determine whether Tweets were related to the disaster or not. This was because manually entering enough Turkish data to train the model was a time-consuming undertaking. In other words, our inability to get the Twitter API service temporarily blocked the progress of this part of our project, but we continue to develop it. If we talk about this part of our project; after trying various models, we decided to try the DeBERTa model for this problem. Since this model is trained with the English language, it has not been able to solve our problem for the reasons I just mentioned, but when we trained the English dataset with our model, we achieved a success rate of 84%. When we prepare a dataset where Tweets are in Turkish, we will be able to use our model easily in line with our project.
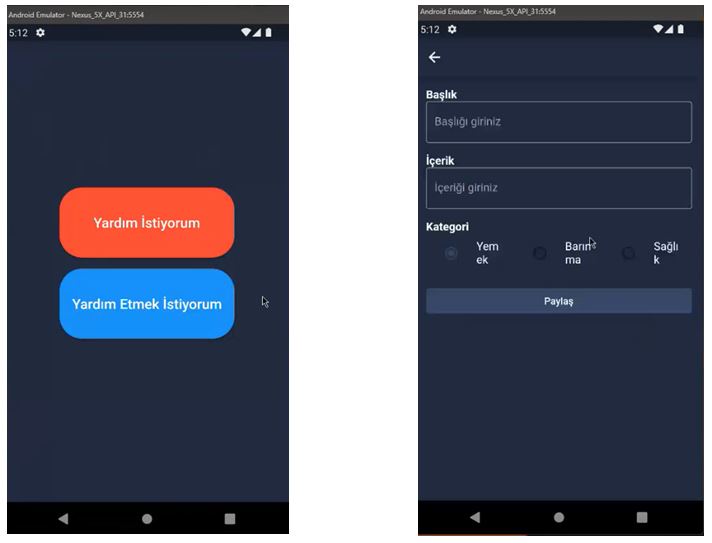
In the field of work we carried out to develop a mobile application, we acted according to the principle that disaster victims can transmit their information directly to the system as the first source. For this, we aimed to make a mobile app that will open smoothly even in bad internet conditions. For this, we decided to make the UI design very simple and functional. We used the Flutter language for this. On the home screen of the application, we used two separate buttons reserved for people who want help and people who want to help. When the person who wants help presses the relevant button, he/she sees a screen where he/she can easily specify his/her need and send it to our web panel. We also wanted to make a section in the application for those who want to help. The aim here is to ensure that volunteers can access the need information transmitted to our web panel from the main page of the application in the form of a post in the application and thus facilitate contact with the disaster victim. This part is still under development.
In the web development part, we first did UI/UX studies for the design of our web panel. At this point, we have designed our web panel and have not yet reached the development stage. When we complete the training of our models and reach the final point, we will write the front-end and back-end codes of the panel. Especially for the back-end, we prioritized the completion of the machine learning part of the project. In addition to the panel, we also wanted to create a Landing Page. The purpose of this is to facilitate the management of site traffic, as well as making it possible to share other content on this Landing Page. For example, showing the earthquake gathering areas of the provinces on the map (we also have a work done for this). During the design phase of this landing page, efforts were made to create an impressive and user-friendly design that would attract the attention of users. The most appropriate color palette and visuals were selected for the user experience. An intuitive navigation structure was designed to improve the user experience. In the content creation section; pages with special modules for various purposes were designed. Buttons were added to access project resources. A change log page was designed to track the versional development and innovations of the project. In addition, a blog and news section was created to be informed about innovations. The technologies used for this landing page structure are; Web Design: WordPress 6.2.2, Elementor 3.13.2 Hosting: MySQL Version: MariaDB 10.3.X, PHP Version: 7.4, Operating System: Cloud Linux OS Optimization: HTML Minification JavaScript Compression and Lazy Load CSS Compression Security: Cloudflare. These technologies will vary according to the standards of the environment where we will take the website live, but for now, this is how it is.
In the part of transferring our website to the internet environment, the container management system we will use is Docker Swarm. The reason we use this is because we want to work with worker and master nodes. When we think about our project, there are containers with different dynamics, running models in the back, doing web scrapping. When we consider their data traffic, we thought that this node management is very functional for situations such as load balancing. On the other hand, the fact that it has a structure that will not cause problems in terms of security is also a factor in our choice to use Docker Swarm. In addition, since we will convert our project into Docker containers and go live in this way, it is also the orchestration tool that will provide us the most flexibility in managing this container structure. Why not Kubernetes? Our project is in a structure that seems to have a certain request density, but it still remains in a much simpler structure for k8s architectures. Especially when we think in terms of cost, the resources (cpu, ram) that Docker Swarm will consume are much more budget-friendly than Kubernetes. Another question is why we don't go even simpler and do container registry and container deployment and pull our site live with Cloud Run in Google Cloud Console. The main reason for this is that the site needs constant database management in the background. The platform we will use Docker Swarm will be AWS. This is because it has affordable and reliable services for systems like Docker Swarm, where dynamic data and updated databases are managed. The service we will use on this platform will be Amazon Elastic Container Service (ECS).