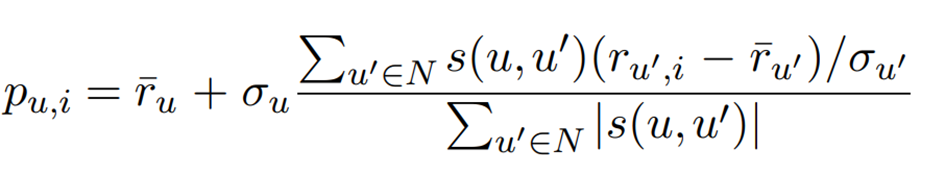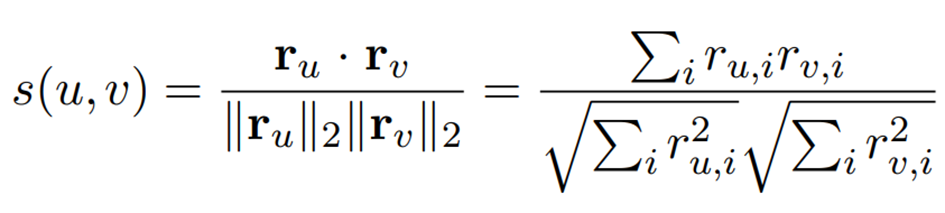Movie Recommendation System
If I were to call myself a cinephile, my first expectation from a movie viewing platform would be to list movies that are suitable for the movies I have watched before, or when I enter a movie name in the search box, I would want to list movies that are close to the movie I entered in certain respects. Based on the first example; for example, I am a registered user of a movie viewing platform and the movies I have watched are stored in the system. Let there be 10 thousand movies in the system, but I have watched only 100 movies among these 10 thousand movies and this data is stored in the system. What I want is to see the most suitable movies for me among the 9900 movies I haven't seen because this is the main reason for my motivation; let's say I'm a user who usually watches comedy movies and so I don't want the system to bring me movies with genres such as horror, thriller, drama. Because if there was no recommendation system on a platform with thousands of movies, the users' homepage would turn into a movie dump. It would be very difficult for a tired user coming home from work or school to browse movies that suit their taste. On the other hand, if we take the second example, let's say I am a tired user who has come home from work and I enter the movie “Harry Potter”, which I have already seen and liked very much, in the search field of the movie viewing platform, but if the platform does not have an algorithm that will give me a “consistent” result, this search will fail. For example, this platform has listed movie titles with the word “Harry” in them, but is that what I want? Or let's say I have already seen the movie “Lord of the Rings” and I want to watch similar movies, so I type that name in the search box, the system might suggest me a movie with the word “Ring” in it or even a movie with the title “Ring” directly. While Lord of the Rings is a drama movie with fantasy elements, Ring is a horror movie, and as a user, it is obviously not among the movies I am looking for. For reasons such as these, it is my top priority as a user that the movies that movie streaming platforms display on the homepage or after the search process are suitable for me.
Before diving deeper into the project, you can also follow the following paragraphs by watching the two Youtube videos I made for the code and presentation of my project:
To build a movie recommendation system, you will need a dataset consisting of "rating" data that users input for movies. Additionally, if you are going to process the tags of the movies, you will need a dataset that contains the movie tags, and if you are considering their genres, you will again need a dataset for that purpose. In short, your dataset needs will depend on the algorithm you want to create. If we consider the algorithm I want to write, the information about users, movies, and ratings will be quite sufficient. Therefore, the dataset I used is the MovieLens1M dataset created by Movie Lens company based on the same problem (movie recommendation system). In this dataset, I used three separate datasets under the names "movie," "ratings," and "links" in my project.
To talk a little about my dataset; in the "movie" dataset, there are three separate columns: "movieId", "title", and "genres". To elaborate; the movieId contains the film's ID number, the title contains the film's name and date, and the genres contain the genres that the film includes. In the "rating" dataset, there are "userId", again "movieId", and "rating" columns. Additionally, there is another column called "timestamp", but there hasn't been a situation in my algorithm that would require the use of this timestamp. In this dataset, every film that users have entered rating scores for is visible. For example, if user 1 has rated 35 films, the userId column in the dataset shows ID number 1 across 35 rows for the films they rated. Furthermore, in another dataset I mentioned, "links", there are 3 columns: "movieId", "imdbId", and "tmbdId". These links, to give an example from IMDb, are the IDs of the film pages on the site. For instance, the ID "0114709" is the IMDb ID of the film Toy Story. My goal was to update each imdbId in this dataset according to the film's IMDb URL and create the following structure: "https://www.imdb.com/title/tt0114709/?ref_=nv_sr_srsg_0". This way, users would be able to access this site, which has a lot of film information, through the algorithm's guidance. However, at this stage of my project, I have not contributed to my algorithm through this dataset yet.
During the project, I made some adjustments to the first two datasets I mentioned. I examined whether the dataset was clean enough to be usable, and then I filtered the data that would be useful for my work. In some cases, I merged these datasets with each other first, and then related them to other merged versions of the same data for different purposes. As can be understood, I made quite a few modifications to the datasets with the aim of providing the most useful and clean data to both my model and the user. In the future, we will discuss these steps in detail.
METHOD
In any recommendation system, two separate filtering methods are generally used: Collaborative Filtering and Content-Based Filtering. In the first phase of my project, I preferred to use Collaborative Filtering, and in the second phase, which I have not yet completed, I am using Content-Based Filtering. First, let me explain what Collaborative Filtering is; the prominent element of this filtering, or even its determining element, is the human. Yes, the data you have previously entered into any system for any product, such as "ratings," serves as a basis for a recommendation system for other users. It is the process of matching users who have similar interests or need a similar product by bringing together user opinions on a specific content. There is a quite classic approach that we often encounter on shopping sites or sites related to this project: "People who liked this also liked that," "People who watched this also watched that."
Collaborative Filtering is divided into two categories: user-user collaborative filtering and item-item collaborative filtering.
The first is user-user collaborative filtering, also known as k-NN collaborative filtering. This method was introduced by GroupLens, to which MovieLens is also affiliated, and it is now widely used as a filtering method. User-user CF searches for other users who have a high agreement (high-related) with the user on the items both have rated, in order to predict the user's preference for an item they have not rated. The scores given by these users for the item in question are weighted according to the level of participation of the user in the ratings.
A user-user CF system requires a similarity function s: U×U → R that calculates the similarity between two users and a method to use the similarities and ratings to make predictions.
To generate predictions or recommendations for a user u, user-user CF first uses s to compute a neighborhood N ⊆ U of u's neighbors. Once N is calculated, the system combines the ratings of users in N to generate predictions regarding user u's preference for an item i. This is typically done by calculating the weighted average of the ratings of neighboring users for i, using similarity as the weight.
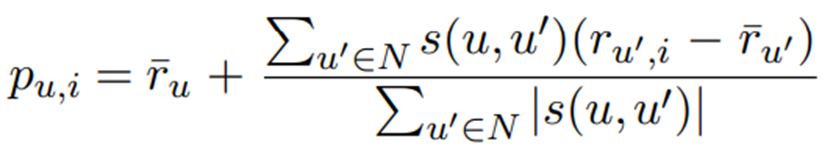
Subtracting the user's average score "¯ru" compensates for the differences in how users utilize the rating scale (some users are more likely to give higher scores than others). The previous equation can be extended to normalize user ratings to z-scores by dividing the deviation from the average rating by the standard deviation of each user's ratings σu, thus compensating for users who differ in the distribution of ratings as well as the average rating:
In this project, I used cosine similarity in the KNN model. Of course, I directly inputted it as a parameter, but if we need to explain it theoretically:
Users are represented as |I|-dimensional vectors, and similarity is measured by the cosine distance between two rating vectors. This can be efficiently calculated by taking the dot product at this point and dividing by the product of the L2 (Euclidean) norms:
RESULTS
If we touch upon my first model, k-NN; I set the number of neighbors to 20, thus dividing the dataset into 20 parts and classifying the movies in this way. If I enter the name of a movie and request a recommendation, the recommendations given to me will be movies from the same cluster. Of course, there is also a hierarchy among the movie recommendations within this cluster, which is "distance." The lower the distance between the input movie and the output movies, the more accurate the recommendation has been.
For example, if I input the Harry Potter movie, my output will be:
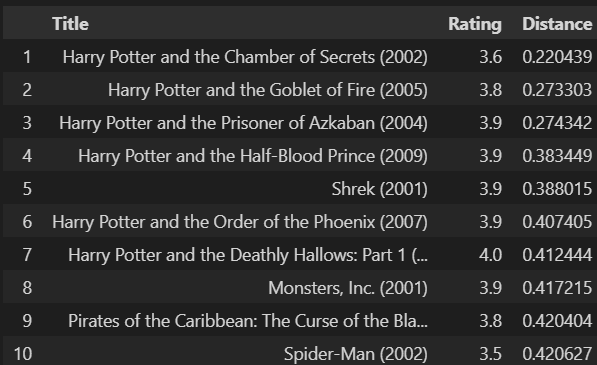
As we can see by looking at the values in the Distance column, we can make determinations among the top 10 most "related" films. Additionally, in the Rating column, I added new scores by taking the average of the ratings given by each user who watched that movie. I generally preferred to explain such dataframe updates in a video presentation.
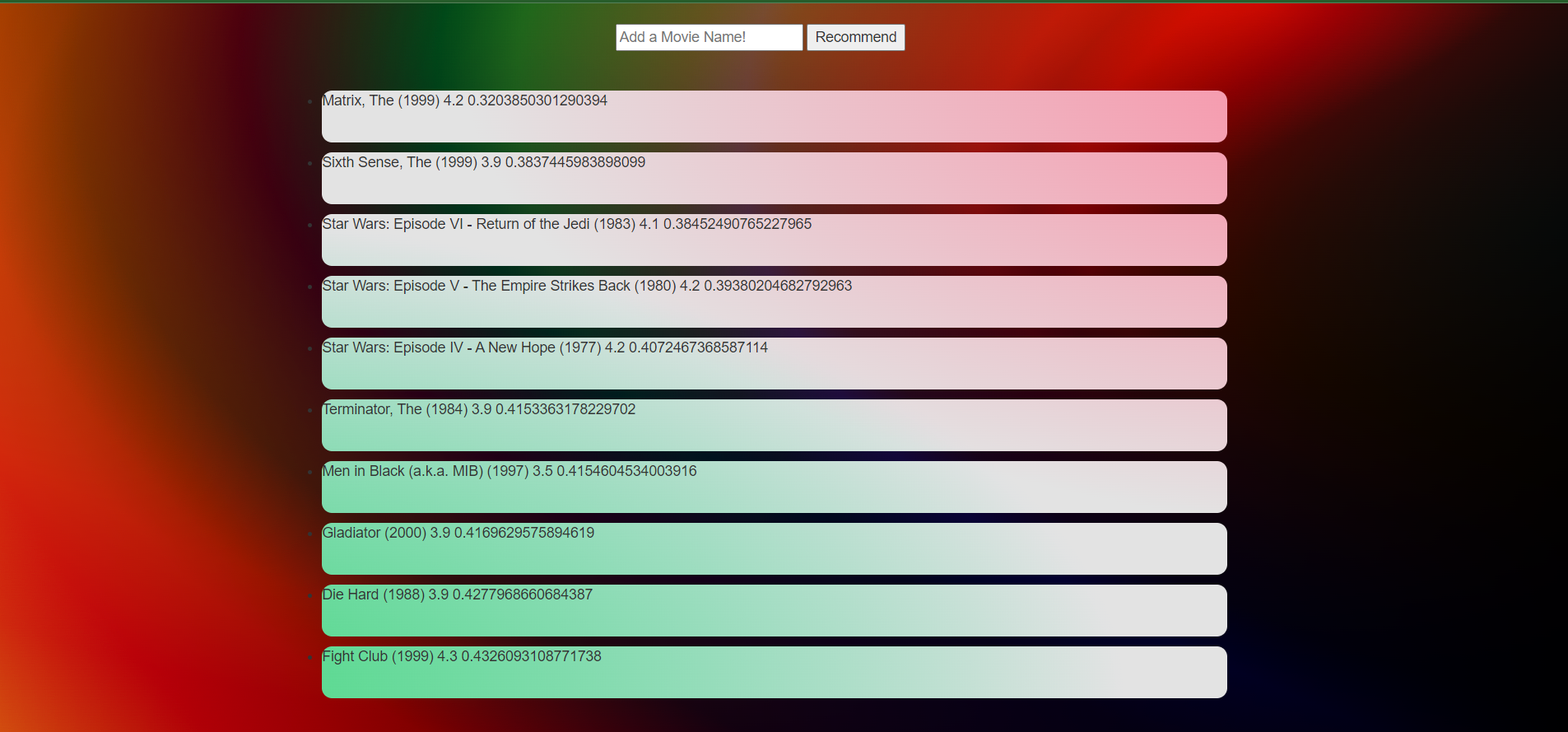
If I were to show my results with a Flask interface:
Movie: Saving Private Ryan
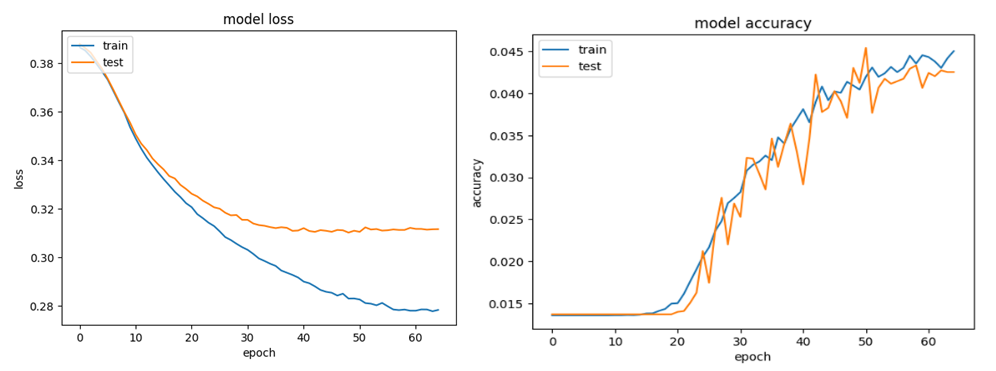
In my second model, I used a deep learning model with the Softmax activation function as the classifier. After setting the learning rate and train-test split (test_size: 0.1), I fit these values to my model and defined 70 epochs.
As can be seen, the accuracy has been steadily increasing and and my loss is gradually decreasing.
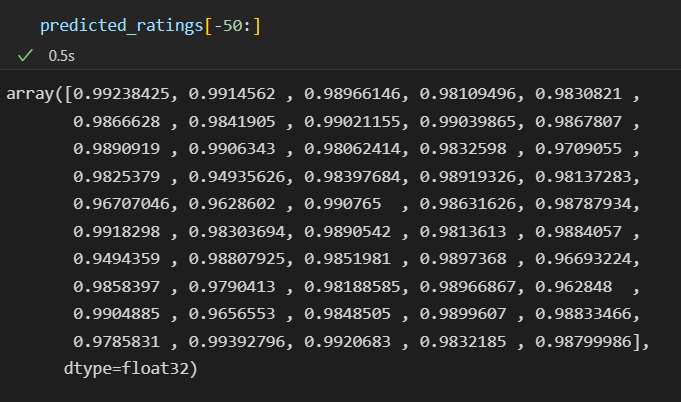
The purpose of this algorithm is to predict the ratings of movies that the user has not watched. As seen in the image, when I requested to show the last fifty predicted rating scores, the prediction results appear to be quite high.
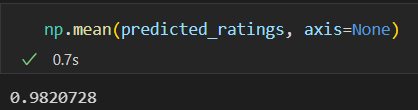
If I were to take the average of the prediction scores;
Now let's talk about the recommendation results of this model:
First, I need to provide a user input so that my model can make rating predictions based on the movies I haven't watched and suggest movies to me accordingly.
I say user_id = 75, and these are the movies recommended by my system:

Additionally, I created another column that shows the actual averages of these movies in our dataset, and for this, I calculated and printed the average of the ratings given by each user who watched that movie. Thus, when a recommendation is made, the movie ratings are also displayed alongside.
Finally, I had another algorithm I aimed for, and its working principle was as follows:
To create a dataset that includes the movies watched by users, along with their rating and genre information, and to learn the genre preferences of users based on the movies they have watched, providing recommendations considering genre and rating parameters for those users. For example, let's list the first 10 movies watched by the user with id 1:
As seen, this list includes the movie title, rating score, and genre. Then, when I sorted the genres of the movies watched by this user, I wrote a code to identify the most watched genre, and the result:
However, due to the large size of the dataset, I could not develop a system that ranks unseen movies according to the user's favorite genre and rating scores, as the iterations took too long and would not meet the deadline. Therefore, it was added to what I would do after submitting my project, that is, the second phase process.