ViT for Social Media Advertising
Today, the impact of social media on commerce is indisputable. For this reason, social media platforms take their place as an important element of the economy today. Speaking of social media and commerce, it would be impossible not to mention influencers. The influencer-follower duo, which we can consider as a very basic example of the seller-buyer relationship, is one of the cornerstones of social media commerce. Developing this trade network is a very important opportunity to gain an advantage in the sector. With the thought of what advantages I could offer to such an area, I started to develop a model that would match advertisers and advertising spaces.
After a day of searching, I realized that the best way to analyze data on a user's profile is to use visuals. For this reason, I did detailed research on Vision Transformers and made notes on how this model architecture works.
I also researched what models were built using Vision Transformers and tried demos from developers on Hugging Face. Then, if the documents of these demos were published, I did research on these documents and read many articles.
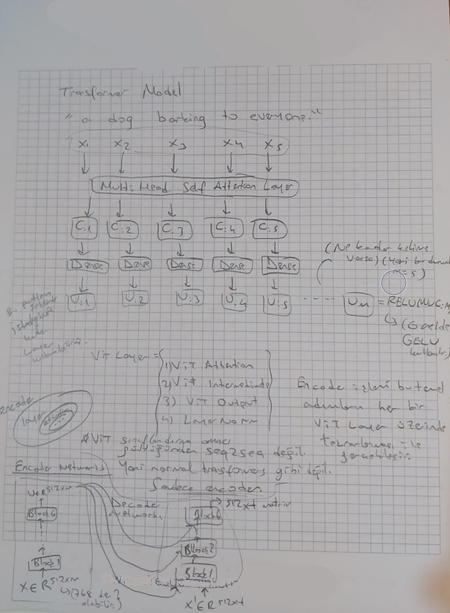
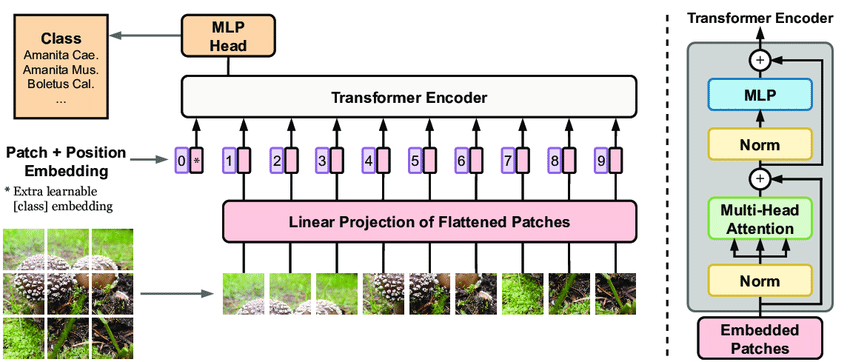
I thought of creating a sentence from images using ViT and classifying that image by giving certain weights to certain words in this sentence, and I developed an algorithm for this, but first, it would be useful to talk a little about why ViT.
Differences Between ViT and CNN
ViT (Vision Transformers) is an approach that adapts the fundamental Transformers model to the field of computer vision. Traditionally, CNNs (Convolutional Neural Networks) have been used in image processing tasks, with convolutional layers being employed to extract features from images. However, ViT processes images by representing them as matrices similar to textual data and then applying an attention mechanism to these matrices. This allows for a hierarchical and contextual understanding of features within images. ViT is known for its flexibility and enhanced learning capabilities when compared to CNNs.
Advantages and Disadvantages of Vision Transformers
The advantages of Vision Transformers (ViT) are quite compelling. Firstly, ViT requires less data from large datasets and often learns faster. Additionally, ViT excels in recognizing objects at different scales, making it effective in tasks such as multi-scale object detection.
However, ViT also comes with certain disadvantages. Firstly, it demands greater computational power and more memory, potentially increasing the costs associated with training and deployment. Furthermore, the performance of ViT compared to traditional CNN-based approaches can vary depending on data sizes and specific tasks.
Vision Transformers represent a revolution in the field of computer vision, surpassing traditional CNN-based approaches, particularly in the context of large datasets. Nevertheless, it's important to determine the best approach for each task. With technology constantly evolving, innovations like VT are expected to continue to shape the fields of computer vision and deep learning. Therefore, keeping an eye on and leveraging new approaches like ViT is a crucial part of advancing in the field of artificial intelligence.
After doing the necessary research for ViT, I had to choose the appropriate ViT model and then develop an algorithm suitable for my problem. As the ViT model, I used the "nlpconnect/vit-gpt2-image-captioning" model developed by OpenAI, which creates sentences with the help of gpt2, but later I met the "openai/clip-vit-base-patch32" model, which does the classification itself after entering the class names and I continued to develop the project using this model.
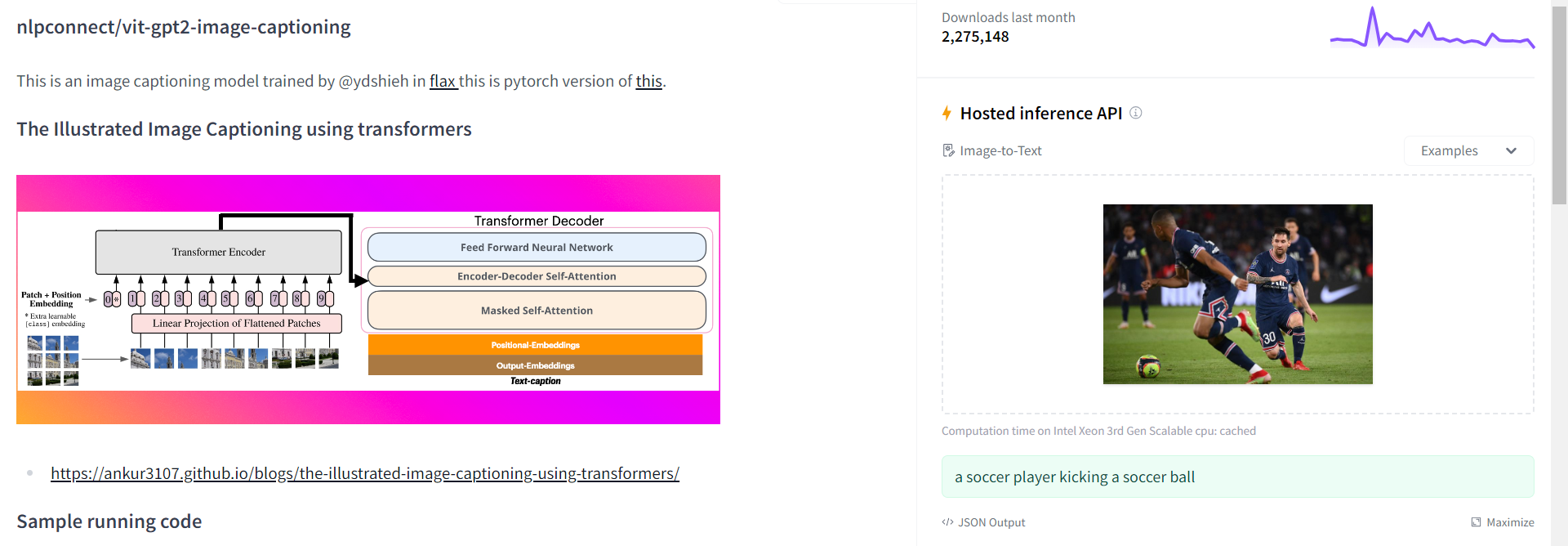
openai/clip-vit-base-patch32 demo:
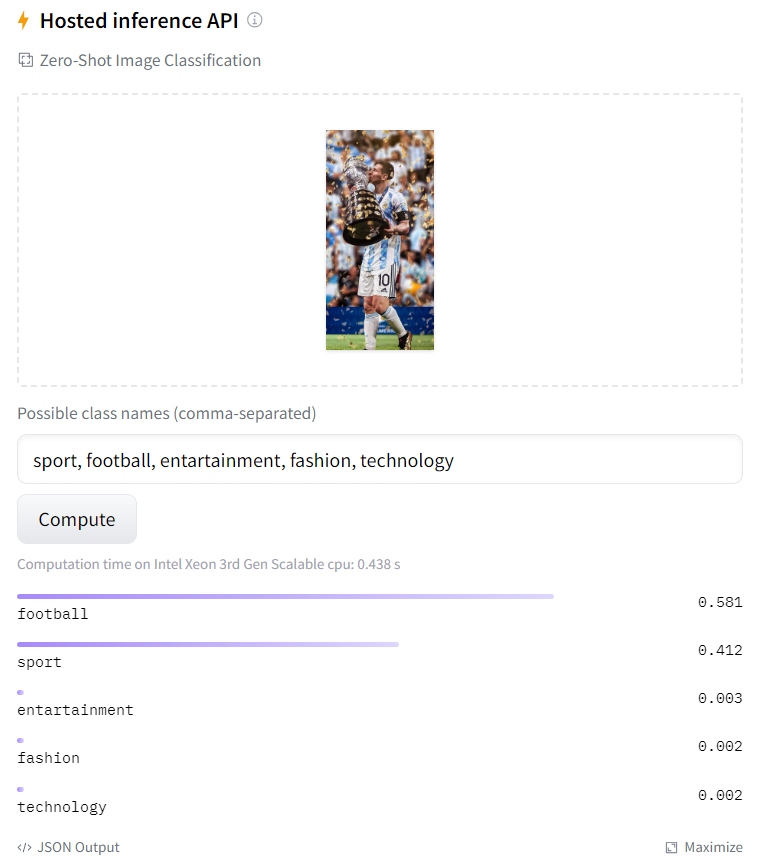
We define the model this way and then create our classes:

When I print the output after the script I wrote, I get the result like this:

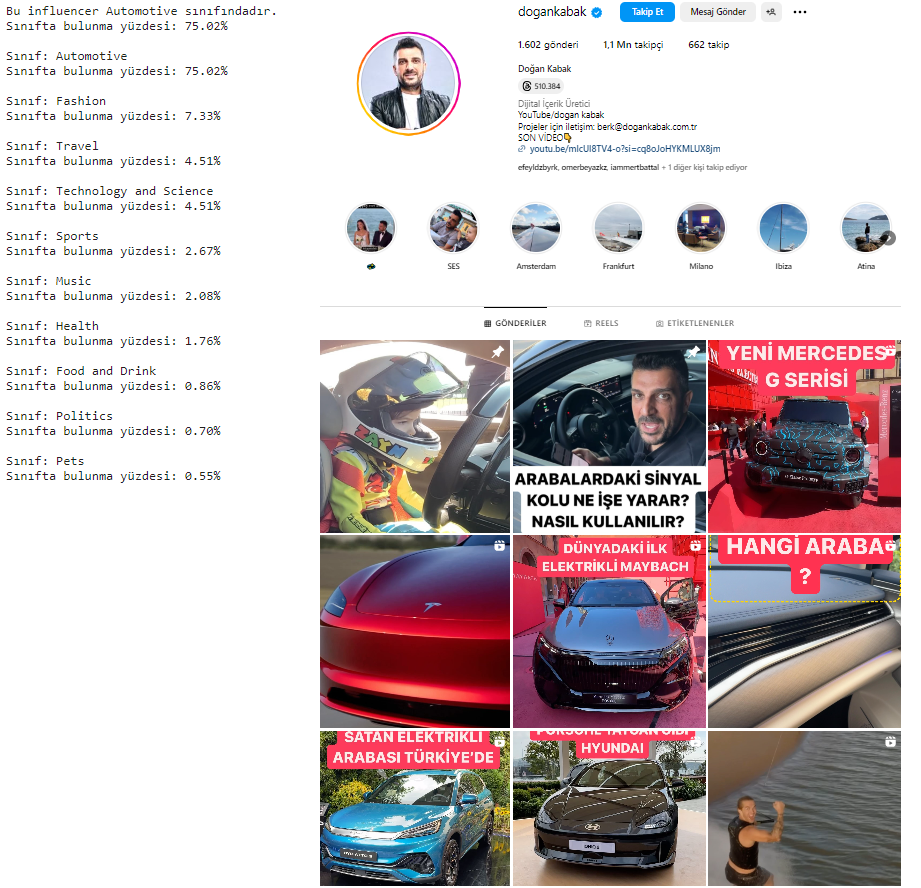
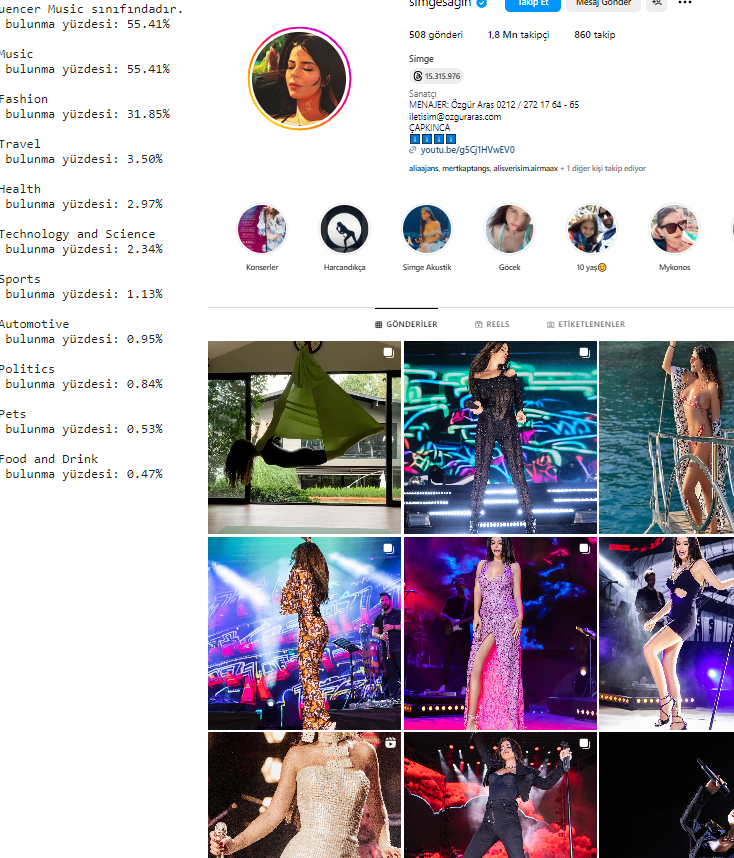
If the person in the photo is an athlete, this is the class with the highest score and we label it as such.
We chose to use Instagram images of social media users as input for this model. In order to make the input automatic, we first did HTML Parsing with Beautiful Soup, and then, with the help of the bot we wrote with Selenium, we managed to download the last 30 images of the person after entering his username. The reason why we downloaded more than one image was that even though an influencer generally shares posts about his/her industry, a single image would be quite insufficient for classification. Therefore, it was most logical to send as many images as we could generalize to the trained model and generate them at the same time.