
New Approach for Word2Vec
The Word2Vec algorithm revolutionized natural language processing (NLP). This approach, which first gained recognition in 2013 when it was presented by Google, represents words using vectors in a mathematical form that captures their meanings. In this way, it models semantic relationships between words so that similar ones are found near each other in the vector space. Many NLP applications benefit greatly from this property such as language modeling, text classification and sentiment analysis among others. Additionally, it performs well on tasks of word similarity and association enabling more advanced predictions to be made by modern NLP methods. Hence, Word2Vec is seen as one of the essential building blocks for contemporary NLP projects.
In this project, we will first create a Word2Vec model and then train with the sentence corpus we have created and extract the vectors of each word.
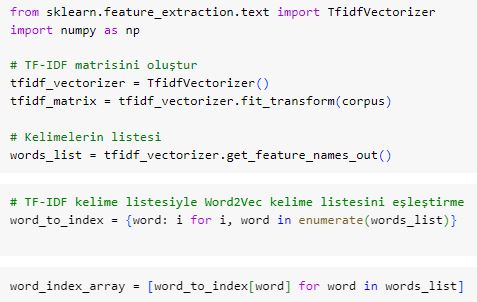
As a new approach, sentence vectors will be obtained by multiplying word vectors with TF-IDF and then our unsupervised sentence corpus will be clustered with the K-Means algorithm. This will give our algorithm the ability to classify unlabeled text data. The corpus we will use at this stage will consist half and half hapiness and unhapiness. The clustering process will be performed on this data and the results will be visualized.
An example word vector space:

The corpus used in the first phase of the project consists of sentences related to Messi:
Model code of the Word2Vec:
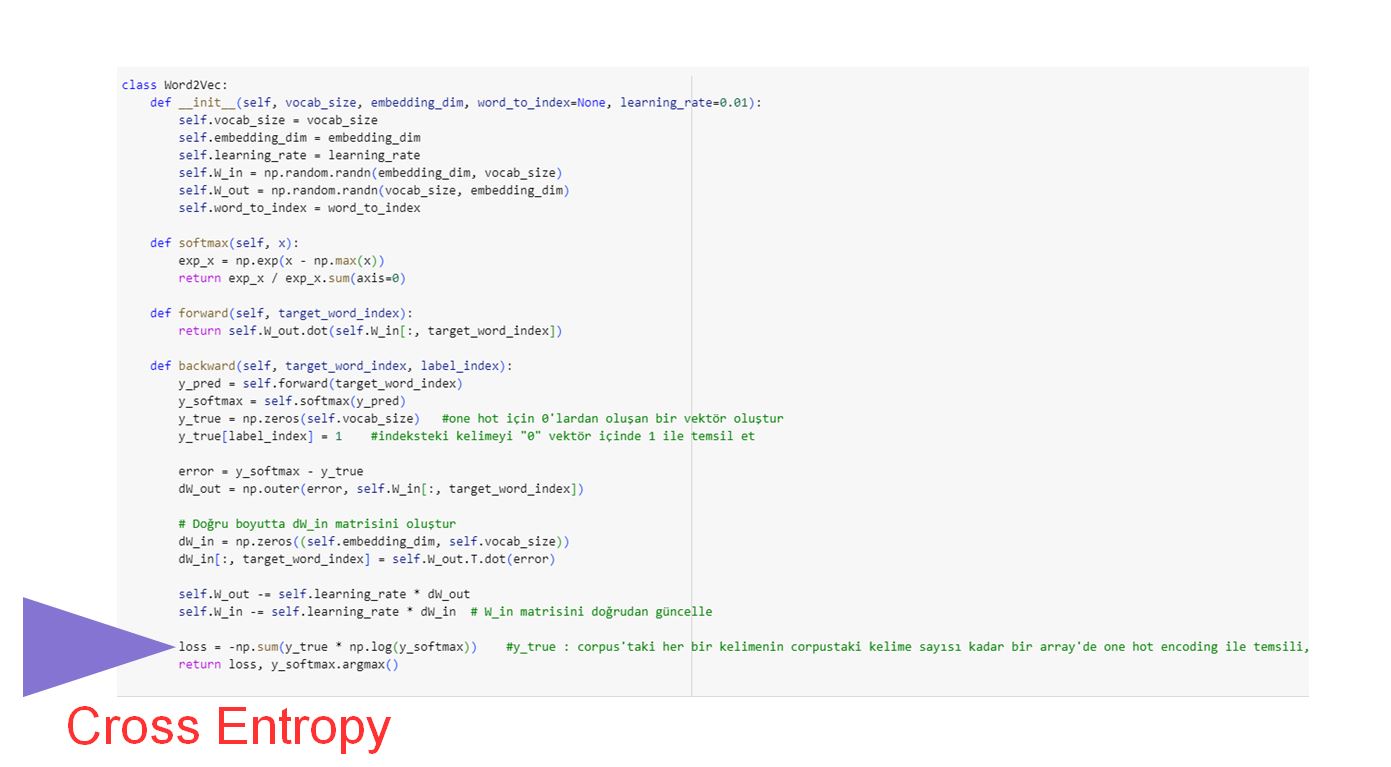
The Word2Vec model is often used as a kind of unsupervised learning algorithm. However, the cross entropy loss function is often used to calculate the losses used during training. Cross entropy measures how well or poorly the model performs by comparing the model's predictions with the actual tags.
In the Word2Vec model, we typically try to predict the context of a word or the words around it. For example, given the word “cat”, the model might predict words like “meow”, “paw”, “fur”. When training the model, a softmax function is used to predict the probabilities of other words in the context of each word. Comparing these probabilities with the actual tags gives the cross entropy loss.
In unsupervised learning, cross entropy is used to measure the difference between the predictions and the actual values, since the labels are not normally available. So, even though the Word2Vec model is trained in an unsupervised way, the performance of the model is evaluated using the cross entropy loss function during training.

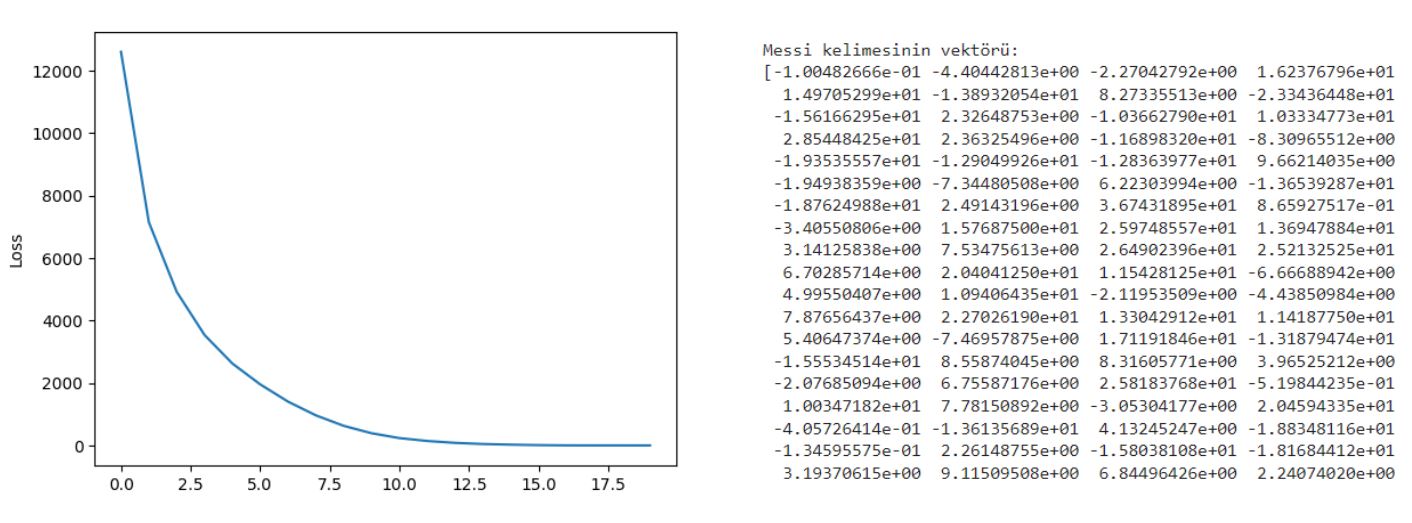
As can be seen in the image below, the loss value gradually decreases as the number of epochs increases, which means that the vector of the selected word is represented more successfully.
Vector of the word “Messi”:
This is where the new approach comes in. If the word vectors of each word in any sentence in our corpus are extracted with the help of the model and then multiplied by the TF-IDF values of these words and kept in a common array, we will extract the sentence vectors and thus we can classify our unlabeled sentences with the help of clustering.

Result of K-NN Clustering Algorithm:
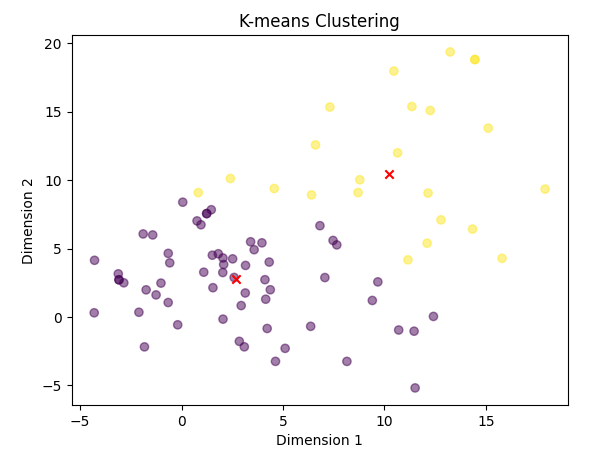
As you can see in the plot, the dots seem to be clustered in two separate places, just like our previously generated sentence corpus. This demonstrates the success of this approach.